ABSTRACT
Data flow machines have been explored since the 1960s. A GALS (globally asynchronous locally synchronous) implementation is explored.
Keywords
Data-flow, synchronous, asynchronous, co-processor, accelerator, GALS, pipeline, concurrency
1. OBJECTIVE
Implement processing elements to process data in a data-flow manner. GALS (Globally asynchronous, locally synchronous) conserves power and allows the fastest operation possible under varying execution times.
Inspired by research I learned on the job at Concurrent Computer, and by ece690's emphasis on data flow, I chose to explore SIMD/vector processors.
Citing [HWA92] Pg. 11
An SIMD computer exploits spatial parallelism rather than temporal parallelism as in a pipelined computer. SIMD computing is achieved through the use of an array of processing elements (PE) synchronized by the same controller.
2. WHAT'S IT GOOD FOR?
It's best suited for streaming data that is processed in the same way, such as array processing, multimedia, image processing, data acquisition.
3. HOW IS IT BETTER THAN TODAY'S CPUs?
1) The data flow model minimizes data motion by bringing the data directly to where it's needed instead of going in and out of temporary registers. Programmers are familiar with the paradigms of procedure-oriented programming vs. object oriented programming. Data flow is the hardware analogy: the data triggers execution as opposed to PCs that obey the Program Counter where the data flow and locations are secondary to sequential program execution.
2) Asynchronous processing offers many advantages
· saves power: not all transitions occur simultaneously and idle units may power-off or stop their clock.
· It's possible to gain speed when one pipeline step completes before the others. Asynchronous pipelines currently suffer delays for the FIFO between units.
Synchronous pipelines are similar to a relay race: both sides are running for the rapid handoff whereas asynchronous pipelines are more like putting work in someone's "in box" and hoping they'll get to work on it soon.
4. MOTIVATION
In the 1980s, Concurrent Computer Corporation made closely-coupled multiprocessor real-time machines for simulators and other critical applications. Everything was their own design from the CPU to the real-time Unix-based OS.
I remember their Navy proposal for a Navier Stokes machine: a massively parallel closely coupled data-flow engine consisting mostly of a crossbar connecting hundreds of ALUs. Since the machine was essentially "single purpose" (solving a fixed set of equations with massive amounts of data) it did not need to respond to dynamic changes in programming.
Years later in NJIT's ECE690, I learned that data flow machines were till barely in use. Professor Ziavras took delight in explaining how Thomasulo's algorithm is close to a data flow machine. While determining data dependencies for parallelism, we learned that there are many ways for hardware to express those relationships and make creative use of that knowledge. Today's concurrency techniques such as register renaming and clever scheduling are all still only second-guessing the intended structure which was lost in the translation from program to machine instructions.
I assert that the statement structure is lost and not expressed directly by machine instructions that depend on intermediate registers. For example: data lifetime is not directly expressed; it's ascertained by register re-use.
By expressing the data dependencies directly to the hardware there's no need for detecting loops for code caching and re-use, no need to determine when a register's value is no longer needed.
Many processors implement
some hint of data-flow by hard-wiring
· the PIC processor has a barrel shifter on the right argument to the ALU
·
· DSP (Digital Signal Processors) often have hard-wired ALUs to support specific filters and algorithms.
Now that FPGAs are being
considered as computational elements, perhaps it's now a valid architecture
since there are more ways to dynamically reconfigure the machine and express
the program's data flow via direct connections of the
5. RELATED WORK
Ivan E. Sutherland's Turing Award lecture on Micropipelines [SUT89] is cited as the foundation for asynchronous processing. His web page http://www.sun.com/960710/feature3/ivan-publish.html notes ongoing research and patents regarding asynchronous pipelines, queue, fifo.
Gregory Wilson's web page "The History of the Development of Parallel Computing" [Wil94] lists the origins of data flow computer concepts and implementations.
Citing "History of Supercomputing"
http://www.interestingpeople.org/archives/interestingpeople/199308/msg00125.html
1968: Duane Adams of
1974: Jack Dennis and David Misunas at MIT publish first paper describing a dataflow computer. (PGW: MIT, dataflow)
1974: Leslie Lamport's paper "Parallel Execution of Do-Loops" appears; theoretical foundation for all later work on automatic vectorization and shared-memory parallelization. (HZ: Lamport, vectorization)
1977: Al Davis of the
1978: Arvind, Kim Gostelow and Wil
Plouffe (at the
1979: The first dataflow
multiprocessor (with 32 processors) becomes operational at
Thomasulo's Algorithm achieves out-of-order execution with a data-flow approach: pending instructions are placed in reservation stations and snoop the results bus for the required input values from previous instructions on which they depend. But there's a bottleneck: there is usually one result bus going to all the stations. Adding multiple results busses adds to the complexity of all the connected elements. Also: the instruction is released once run instead of being retained for re-use in a loop.
A crossbar switch eliminates bus contention by connecting each producer directly to the consumer via a dedicated path, but adds complexity for the interconnection and synchronization of the processing elements.
Most
Whereas general purpose computing seeks to maximize functional unit utilization and execution parallelism, SIMD co-processors are best for repetitive calculations on data streams or arrays.
6. RECENT SUCCESS
The following asynchronous CPUS are in production:
The
ARM And Philips' Handshake
Solutions produces Clockless Processor http://www.arm.com/news/6936.html
At the ASYNC 2001
conference, Sun Microsystems Laboratories described FLEETzero, a prototype chip
with raw speed roughly twice that of today's chips. Where today's chips use
"synchronous" circuits with a global clock to manage activity, the
new, faster FLEETzero chip uses radical new circuits with low-power,
asynchronous logic elements that produce timing signals only where and when
needed. Turing award winner Ivan
Sutherland leads the Sun group.
http://research.sun.com/features/async/
7. co-processor vs. accelerator
The proposed system can be interfaced either as a coprocessor or as an accelerator, depending on the CPU's ISA.
7.1 Co-processor
ADVANTAGES:
· closely coupled to the CPU, executes instructions in the program stream
· uses the CPU's cache and MMU for faster, coherent memory access
· greater process coordination via co-processor instructions
DISADVANTAGE:
· design is specific to CPU architecture and version
CURRENT IMPLEMENTATIONS:
The ARM and Intel x86 family
explicitly support coprocessors with appropriate commands for register loading,
storing and coprocessor control. Intel's
7.2 ACCELERATOR:
ADVANTAGES:
· loosely coupled to the CPU, operates independent of the instruction stream
· external to CPU, independent of the CPU
DISADVANTAGES:
· slower communication and synchronization
· programmed via external registers
· even with scatter/gather DMA/bus-mastering
o the data must be properly organized
o O.S. must assure coherency (lock page-in-core
o application must assure coherency (no data modifications while busy)
· shared memory is still expensive
CURRENT IMPLEMENTATIONS
· graphics/video controllers
· SCSI, ATAPI, I/O controllers
· FPGA
8. OBSTACLES
TO DATA FLOW MACHINES
Computer architecture is
evolutionary, not revolutionary.
Part of the "baggage" of this evolutionary process is that CPUs still work essentially the same as the first computers: a program counter dictates the execution of instructions. Data flow is secondary, being shuffled in and out of registers and memory.
Citing http://www.csis.american.edu/tbergin/pubs/specialissue_annals.html
The final programming language article in this issue examines a class of languages. In "A History of Data-Flow Languages," Paul G. Whiting and Robert S.V. Pascoe define the data-flow paradigm, explore its origins, and identify the major languages and dialects. In doing so, Whiting and Pascoe identify the individuals and research projects that have focused on the development of data-flow languages; the authors also identify the major elements in the data-flow literature.
Since data-flow languages are not widely used or understood, Whiting and Pascoe provide the reader with an introduction to the language class and to the data-flow models. After a discussion of efforts to create and program data-flow machines, the authors idenify the features of data-flow languages, as defined in Ackerman's February 1982 Computer article, "Data Flow Languages.” A discussion of the functional languages that were influential in the evolution of data-flow languages is followed by an extensive discussion of nine data-flow languages and a number of graphical languages. The authors conclude their efforts by stating, "Whether data-flow will simply fade away to leave no more than a legacy for other developments...cannot be known in this decade." Whatever the outcome, this article provides the reader with an excellent starting point from which to evaluate that outcome.
which in turn references: A history of data-flow languages
Whiting, P.G. Pascoe, R.S.V. Div. of Inf. Technol., CSIRO,
In the "data flow" paradigm, the data dictates what happens. Ideally, such a machine would have no program counter, just a state machine triggered by the arrival of data.
Object-Oriented Programming and Design is a high level view of data flow. Instead of data existing separate from the procedures, data is self describing: it has methods for creation, deletion, processing and collaborating with other objects. Even with Object Oriented languages such as C++ and Java, the end result is still a stream of instructions with data moving amid registers for varying durations.
There are several ways to narrow the gap between the expression of the problem and the machine's execution.
· static analysis
·
VLIW / SIMD (
· loop unrolling, optimizers
· co-processors and accelerators (reprogrammable or fixed-function)
· dynamic exploitation
· cache anticipating memory access
· branch prediction
· code re-use
· out of order execution
· hyperthreading
8.1 Why speculate when you can be told?
Most modern CPUs dynamically rename registers for out-of-order execution and simultaneous execution by mapping instruction dependencies.
Consider this data dependency:
e = (a+b) * (c-d)
When the compiler parses the statement, the dependencies are represented by tree structures, but that's not evident in the resulting executable code. The machine code uses intermediate registers such as:
load R1 with A
load R2 with B
add R1 and R2 giving R3
load R1 with C
load R2 with D
subtract R2 from R1 giving R4
multiply R3 and R4 giving R4
store R4 as E
Nowhere is it explicitly stated that the values of R3 and R4 can be discarded. It can be ascertained only by seeing an instruction that loads R3 or R4 without any intervening access.
If there were a way for the compiler to tell the machine the statement structure, there would be no need for the machine to re-evaluate the way the statements work together since that never changes.
A data flow machine arranges functional units with the inputs directly connected to the FE inputs the same as the dependency graph:
a b c d
alu alu
alu
e
There's no need for
intermediate registers because the link between the ALUs describes the data
dependencies. Data that is truly
transitory requires no explicit registers: they're in buffers/fifos between
8.2 Programming language support
Data parallel languages exist such as NASM, Vector Pascal, CC++, High Performance Fortran (HPF), but most SIMD support is via C++ classes, libraries and compiler support particularly for loops [COC04].
Citing [HWA92] Pg. 556:
The
development of
9. IMPLEMENTATION
This project focuses on an accelerator that is smaller and less ambitious than the Concurrent Computer Navier-Stokes machine.
To simplify the implementation, the magnitude was significantly reduced
· register only operation, no direct memory access
· 4 input buffers
· 4 ALUs
· an 8 x 8 crossbar for fully symmetric connectivity
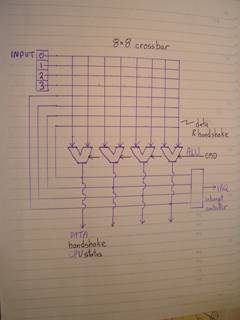
This is best implemented as a co-processor for systems with native co-processor support such as the ARM which has instructions for loading/storing the co-processor registers and issuing commands.
For systems without explicit co-processor support, this may be interfaced as an accelerator: the registers are mapped into memory or I/O space and loaded explicitly as an external device. The CPU cache must handle the memory region as "volatile" registers that cannot be cached.
10. The co-processor architecture
10.1 TERMS USED
FE: functional element: a buffer or ALU
All data is transferred asynchronously. 2 handshaking lines are used: a "ready" line to indicate that the data is valid and ready for the taking, and "acknowledge" for releasing the input buffer.
10.2
ALU
control lines
Each
IDLE FE is waiting for initialization
clock is stopped
READY FE is ready for work, buffer is empty
clock is stopped
clock is running
WAIT FE has completed work, data is in buffer
clock is stopped
"ready" line is asserted
waiting for data to be read and acknowledged
The states are important for determining when all the computations are completed, and to assure that ALUs not participating in the calculations do nothing.
Before any data is loaded, each
[unit-addr] is the address
of the
[l-input] is the left input
(an input buffer or output of an
[r-input] is the right input
(an input buffer or output of an
[instruction] is the operation to perform.
Some take no input, others only the left input.
Logical operations operate bitwise on the entire word.
Arithmetic operations are specific to the data type:
· signed or unsigned
· fixed or floating point
·
1: 64 bit,
There are 133 Intel SIMD instructions due to the data type combinations. Here are a few of the instructions for these ALUs:
NO-OP (do nothing)
OR
XOR
NAND
NOR
NOT
ADD-packed-single-precision
COMPARE-single-precision
CONVERT-integer-to-floatingpoint
Here, the NO-OP is more like
a sleep or doze mode: the
11. Principles of operation
Each FE is considered a
"black box", free to use any technology appropriate for achieving its
results. It may be synchronous
clock-based, so long as it starts processing when data is received. If the clock starts upon data reception
instead of running all the time, time can be saved by never having to wait for
the next clock edge just to latch the input and start computation! It is advantageous to stop the clock when not
In its initial state, all elements are READY; contain no data and are not initialized. ALUs are initialized to the IDLE command: do nothing even if data is present at input. This prevents unused ALUs from taking data since inputs are always pointing to a valid source and the crossbar will not present data to an IDLE FE.
Before any data is presented
to the system, all participating
For operation,
· data is latched into the input buffers
·
data is read from the
Instead of polling or blocking the reads, an interrupt is generated when all outputs are ready: A level-triggered interrupt is signaled for
((
(
AND
((
(
AND
((
(
AND
((
(
That way, the interrupt occurs only when the data propagates thru the active ALUs.
For streaming data, operation proceeds as follows
· latch the input data
· upon interrupt
o write all required input buffers
o read data from all active ALUs
The interrupt automatically
resets upon any data read due to buffer acknowledgement. By writing the data BEFORE reading the
output, the data is held in input buffers and will be consumed the moment the
receiving
In operation, the data flows as follows
· buffers hold data until released,
· cannot write input buffers until data is consumed
· cannot read final buffers until data is ready
By reading ALL output, then writing ALL input the machine state is coherent
For example, to add 2 arrays together:
1.
set
2.
set
3. for each pair of data
a. load the 2 numbers into input buffers
b.
store the result from
An optimization uses 2 ALUs for 2 additions at the same time
1.
set
2.
set
3.
set
4. process 2 pairs at a time
a. load one pair to input buffers 0,1, the other pair to buffers 2,3
b.
store the results from
A "worst case" example: all elements are serialized so no parallel operations can occur:
(A+B)*C+D
the result must ripple thru 3 ALUs.
A B
+ C
* D
+
12.
SIMULATE THE ARCHITEC TURE
simGALS is the appropriate simulator for a globally asychronous architecture. The ALUs may be synchronous in order to use existing technology but treat them as "black boxes" and all the connectivity is asychronous.
simGALS supports the Alpha or Pisa CPUs, neither of which has co-processor instructions. Happily, undefined opcodes cause a TRAP condition, this allowing emulation of new instructions. Co-processor instructions can be added to the program and code in sim-gals.c gets invoked when the TRAP condition is raised, thus emulating the co-processor!
It's also possible to modify the target-specific code and add co-processor instructions, but that's modifying the underlying ISA.
Either way assures that the simulator code is part of the main engine with the full environment for using the machine registers and profiling. Simulating an accelerator is more difficult because the simulator would need to emulate hardware working outside the CPU and retain the timing relationships for when data is ready.
12.1
TO PROV E
IT WORKS
Write and run test programs for arrays and loops, profiling the time elapsed and FE utilization. Compare that to the speed & power of
· using NO co-processor
·
using a contemporary SIMD with same number of
similar ALUs (such as
A moderate speedup over current SIMDs is anticipated due to
· no need to re-issue instructions each time
· less register load/store
13. Future Work
· make it easier to use!
· more ALUs, larger crossbar
· add internal registers (summation, n-1/delayed data)
· faster interface (ie: clear all outputs instead of reading them all or dedicated output buffers or output FIFO)
14. Refernces
[1] [ARM00] ARM Limited. Integrator/LM-XCV400+ Logic Module. Feb 2000 www.arm.com
[2] [COC04] Paul Cockshott, Kenneth Renfrew. SIMD Programming manual for Linux and Windows. Springer, 2004. ISBN 185233794X http://www.dcs.gla.ac.uk/~wpc/SIMD.html
[3] [HEN02]
John L. Hennessy, David A. Patterson, David Goldberg. Computer Architecture: A Quantitative
Approach. Morgan Kaufmann; 3rd edition (
[4] [HWA92] Kai Hwang. Advanced Computer Architecture: Parallelism, Scalability, Programmability.. McGraw-Hill, 1993. ISBN: 0071133429
[5] [IYE02] A. Iyer and D. Marculescu. Power-Performance Evaluation of Globally Asynchronous, Locally Synchronous Processors. In Proc. Intl. Symposium on Computer Architecture (ISCA), pages 158--168, Anchorage, AK, May 2002.
[6] [RAF95]
Mohamed Rafiquzzaman. Microprocessors
and Microprocessor-based System Design.
[7] [
[8]
[VCC98] Virtual Computer Corporation
"Hot II Architecture" http://www.annapmicro.com/
[9] [
[10] [WIL94]
Gregory V. Wilson. The History of the
Development of Parallel Computing. http://ei.cs.vt.edu/~history/Parallel.html
[11] [WOL01] Wayne Wolf. Computers as Components. Morgan Kaufmann, 2001
[12] http://www.levenez.com/lang/ Computer Languages History & Timeline
[13] http://people.ku.edu/%7Enkinners/LangList/Extras/langlist.htm
The Language List Collected Information On About 2500 Computer
Languages, Past and Present.
[14] http://www.uweb.ucsb.edu/~wasim/homepage_files/StrongARM1.doc
CS 263 Project Report. ARM Architecture Simulator Installation [
[15] google
"lpx asynchronous"
[16] google
"lpx ipcmos execute"
[17] www.ece.cmu.edu/~dianam/micro02/micro-3.pdf
[18] www.ece.cmu.edu/~dianam/ics02/ics-3.pdf
IPCMOS section, Schuster and Cook,
[19] www.eecs.harvard.edu/~dbrooks/pacs2002.pdf
... In
[20] http://www.fpgacpu.org/usenet/fpgas_as_pc_coprocessors.html On FPGAs as PC Coprocessors
14.1 To learn more about "data flow" architecture
[21] http://www.research.ibm.com/dx/proceedings/dx_paper/
An Extended Data-Flow Architecture for Data Analysis and Visualization. Greg
Abram,
[22] http://portal.acm.org/citation.cfm?id=801884
A multi-user data flow architecture. Proceedings
of the 8th annual symposium on Computer Architecture.
14.2 to learn more about FPGA accelerators
[23] http://www.arm.com/products/DevTools/IntegratorLM-EP20K1000E.html Integrator Altera Logic Module
[24] http://www.arm.com/news/360.html ARM
Extends Integrator Board Family With Launch Of Logic Tile Product.